ICM / partners / ¿Problemas con Snapshots en Nutanix?
¿Problemas con Snapshots en Nutanix?
29 agosto 2020 | Ricard Forn
Hola mis queridos sufridores y sufridoras de problemas con Nutanix ?, en la entrada de hoy tocaremos los snapshots. Y es que ¿quién de vosotros no se ha encontrado con alertas del tipo Aged third-party backup snapshots present? ¿O ha visto como sus discos se llenaban de forma incomprensible con snapshots que no pertenecían a ninguna máquina virtual?
En ambos casos Prism (Elements o Central) no nos sirven de nada y, como en casi todos los problemas que nos encontremos con Nutanix, deberemos de entrar por consola y utilizar los comandos adecuados. Por este motivo, en esta entrada de blog trataremos los problemas, con diferencia, más molestos: el tener snapshots “viejos” de terceros.
Soluciones a problemas comunes con snapshots de Nutanix
Esta alarma se presenta cuando normalmente utilizas un software de backups (Hycu, Veeam, Rubrik, …) y estos tienen generado un snapshot que supera el umbral máximo especificado en la política de Nutanix. Ya sea porque así lo hemos definido con una retención muy larga de snapshots, o bien porque se ha producido un error en el software de backup y el snapshot que normalmente realizan para hacer la copia no ha sido eliminado.

La alerta por defecto en Nutanix tiene un umbral de 7 días. Si son necesarios más días (por que tu software de backups guarda snapshots con más antigüedad…) se pueden modificar los límites de la alerta y subirlo para que avise a los 14 o 31 días, por ejemplo.
Para ello, primero debemos de ir a Alerts > Configure > Alert Policy

Realizamos una búsqueda por la Policy que queremos editar buscando por aged. A continuación, clicamos en el lápiz para editarla. En nuestro caso hemos definido el umbral de Warning a 32 días (un día de estos ya explicaremos trucos de HYCU en el blog).

Más problemas
Si por lo contrario, tu software de backup ha tenido problemas y no ha eliminado los snapshots, tenemos otro problema. Lo que recomienda todo el mundo es utilizar el comando de cerebro:
cerebro_cli query_protection_domain tu_protection_domain list_snapshot_handles=»true;scoped»
Para obtener tu protection domain de sistema que no aparece en la lista de protection domains puedes aprovecharte de un pequeño bug. Así, simplemente tienes que hacer clic en Protection Domain de la misma alarma y te llevará a la sección de Data Protection con un error que el protection domain no fue encontrado. ¡Pero eso es mentira!
Simplemente no lo muestra en el portal web, es el Protection Domain por defecto de sistema. Seguro que hay el comando de consola para sacar listado de protection domains, pero adoro estos bugs que nos facilitan la vida y muestran información útil y rápida.


Volvemos al lio. Tal y como he indicado, la forma que recomiendo todo el mundo está bien si manejas unos pocos snapshots y lo puedes identificar fácilmente. Pero en el caso de ICM que manejamos de forma regular más de 1000 snapshots y no es viable ni asumible, el truco fácil está en hacerlo vía cerebro.
Os dejo un link que a día de hoy es vigente con los nombres de los Servicios de Nutanix y sus funciones principales. La lista no es corta precisamente.
Snapshots vía cerebro
Para ver los snapshots vía cerebro nos conectaremos mediante SSH a la IP del cluster de Prism Elements (CVM Master). O también, a priori, desde cualquier IP de CVM (debería de redirigir al master cuando luego nos conectemos al servicio) y ejecutaremos el navegador links a localhost puerto 2020: links http://localhost:2020
Dar un curso de links requeriría varias entradas de blog. La versión resumida sería: cursores arriba-abajo para desplazarse por los links, cursor derecho para hacer clic en ellos o cursor izquierdo para volver atrás y “q” para salir.
Seguimos: hacemos clic cursor izquierdo en nuestro Master Handle.

Buscamos la sección Entity Centric y en la columna name seleccionamos nuestro Protection Domain (recordar, desplazarse con cursores de arriba y abajo, derecha para seguir el link).

Y obtenemos el listado de todos los snapshots de dicho Protection Domain, ordenados por fecha de antigüedad de más antiguo a más nuevo. En la captura podemos ver un snapshot que supera nuestro baremo y que debemos arreglar.

Cursor derecho sobre el handle para ver más detalles y después de tres clics y llegado al último detalle, tendremos el nombre de la VM causante:
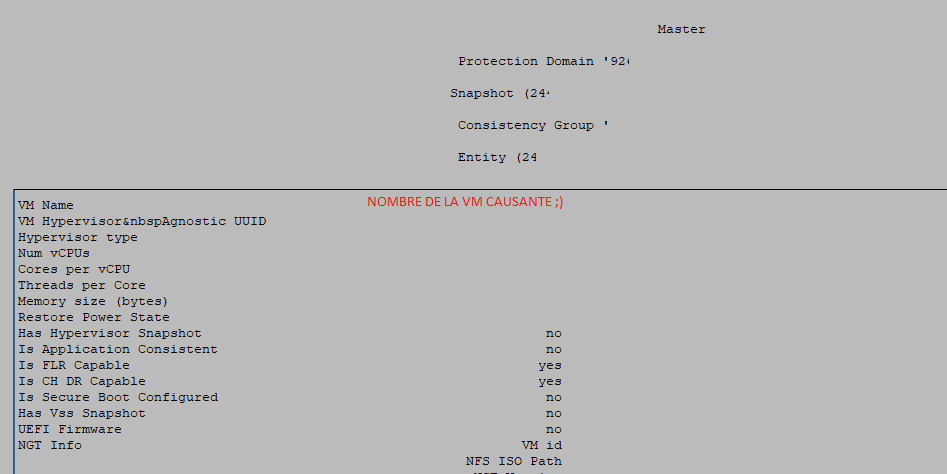
A partir de aquí, sabiendo la máquina virtual, el snapshot y la fecha, lo ideal es eliminarlo desde el propio software que lo ha generado (HYCU, Veeam,…). Si no es posible eliminarlo desde el propio software de backup, entonces lo mejor es abrir un ticket con dicho fabricante para que nos den una solución ante dicha incosistencia.
Solución final a fallos con snapshots
Pero para los más atrevidos/kamikazes o bien para los que saben mucho lo que se hacen siempre está la opción de eliminarlo desde la consola de una CVM: cerebro_cli modify_snapshot snapshot_uuid=<snapshot-uuid> expiry_time_usecs=`date +%s`
El snapshot UUID lo podéis obtener dos capturas atrás. En cada handle aparece su UUID, solo tenéis que cambiar <snapshot-uuid> y poner el UUID.
El truco está en que no puede ser eliminado y simplemente le ponemos una fecha de caducidad del snapshot igual a la fecha actual más un segundo. Por defecto, caducan en el año 2088 (ojo que si alguien lo tiene encendido 68 años más se puede encontrar unos cuantos problemas y perder snapshots que quizá quiera conservar).
Si salís de links y volvéis a entrar y vais a vuestro Protection Domain ya habrá desaparecido al estar caducado, os aseguro 100% que funciona. Ya solo os queda ejecutar un ncc check para validar que esté todo bien. Así, podéis ejecutar estos tres checks directos: ncc health_checks data_protection_checks protection_domain_checks aged_third_party_backup_snapshot_check
Eso es todo queridos lectores, mil y una gracias a los que habéis llegado hasta el final (y también al resto).